1. Target 페이지 식별
크롤링에서 가장 먼저 해야 할 작업은 원하는 자료가 위치한 웹 페이지 주소를 정확하게 파악하는 것입니다. 물론 주소표시줄을 확인하는 것만으로도 대부분 해결할 수 있는 문제이긴 합니다. 그러나 세상 일이 그렇게 간단치는 않죠. 예외적인 상황이 많기 때문에 브라우저의 구조와 작동원리를 좀 더 자세히 살펴볼 필요가 있습니다.
페이지 속의 페이지??
인터넷을 통해 우리가 눈으로 확인하는 내용은 한 페이지의 문서에 불과합니다. 그러나 그 한 페이지의 문서를 실제로 웹브라우저에 구현하기 위해, 브라우저 내부에서는 눈에 보이지 않는 많은 일이 벌어지고 있습니다. 목표로 하는 정보가 표시된 웹 문서의 정확한 URL을 확인하려면, 무엇보다도 브라우저 내부의 동작 및 서버와 브라우저 사이에 오가는 신호를 체크해야 합니다.
예를 들어 살펴보겠습니다.
네이버 증권에서 KOSPI 지수 일별 시세의
지난 10년치 기록을 가져온다고 가정해 봅시다. 처음 주소창에 네이버 증권 국내증시의 주소를 입력하고 해당 페이지로 이동1 한 후
F12키2를 누르면 Figure1과 같은 화면이 나옵니다.
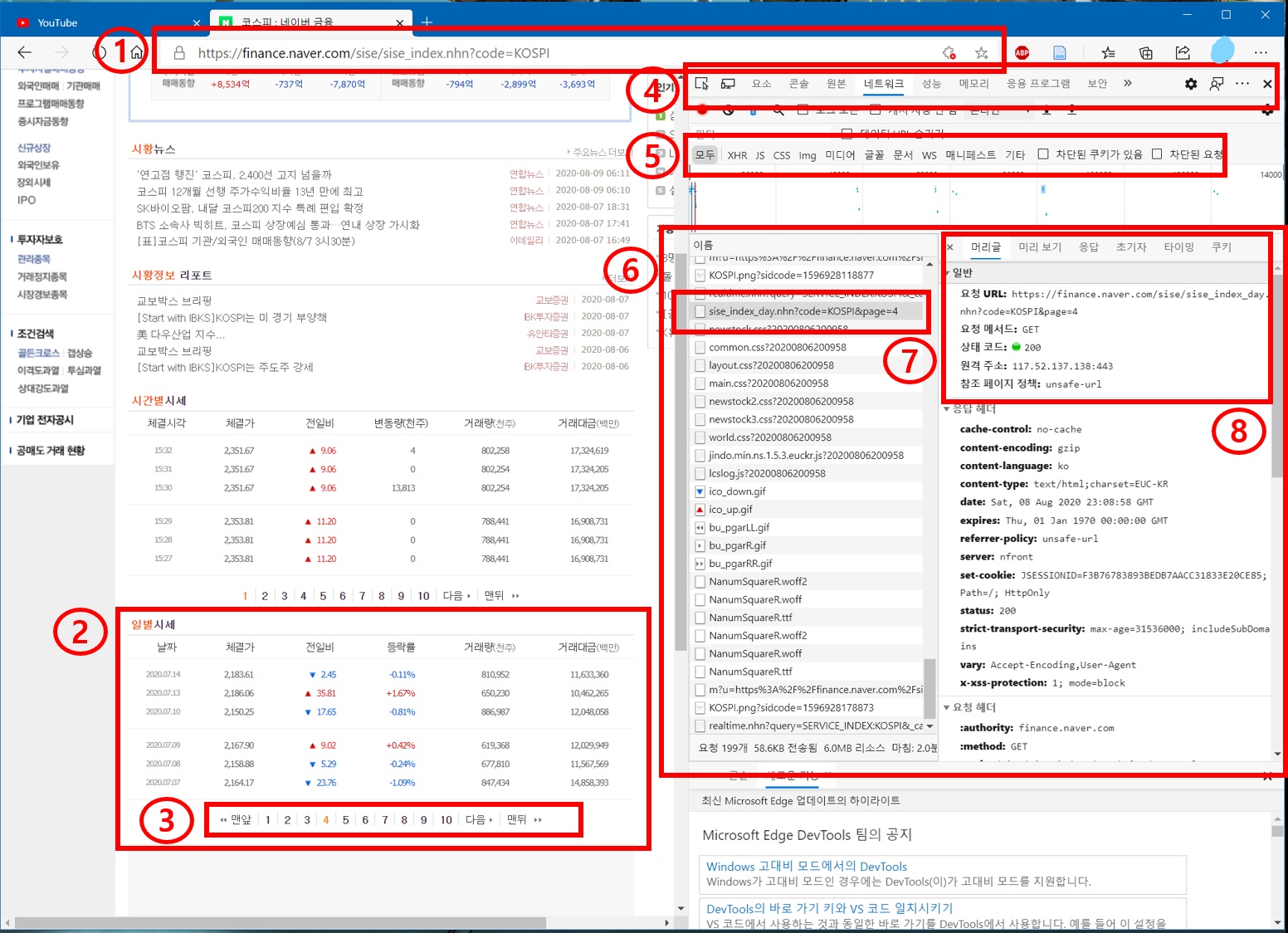
Figure 1: 웹 페이지 구성
Figure1에서 KOSPI 일별 시세에 대한 정보는 페이지 하단의 2번 구역에 위치하고 있습니다. 가만히 살펴보니 첫 화면에서는 최근 6일에 대한 시세 정보만 제공하고 있네요. 최근 6일치 말고 그보다 더 전의 시세에 대한 기록을 찾아보려면 3번위치에 있는 페이지 숫자를 일일이 마우스로 클릭해야 합니다. 페이지 숫자를 클릭할때마다 예전 시세정보를 6일치씩 끊어서 볼 수 있도록 사이트가 구성되어 있습니다.
근데 3번의 페이지를 누른다고 해서 1번주소표시줄의 URL이 변경된다거나 그러지는 않습니다. 3번 페이지를 클릭하면 새로운 일별시세 정보가 갱신되는데 주소표시줄의 URL은 그대로입니다. 즉, 1번 주소표시줄만 봐서는 과거 KOSPI 시세 정보를 노출시키는 URL을 정확하게 알 수 없는 상황입니다. 이때 봐야할 곳이 웹브라우저의 개발자도구의 네트워크 탭입니다.
네트워크 탭에서 서버와 브라우저 사이에 오가는 신호를 확인하자!
크롬에서 F12키를 누르면 개발자도구가 활성화 됩니다. Figure1의 오른편 처럼 말입니다. 가장 처음 확인해봐야 할 것이 4번 위치의 네트워크 부분입니다. 인터넷을 할 때, 웹 브라우저를 통해 서버와 신호를 주고받는데 네트워크 에는 서버와 브라우저 사이에 오가는 모든 신호정보가 표시됩니다. 즉, 코스피 지수의 과거 시세 정보를 보기 위해 3번의 페이지 숫자를 클릭하여 시세 정보를 갱신하게 되면 그 신호 정보가 네트워크에 표시된다는 이야기 입니다.그럼 다시 코스피 시세정보의 URL을 어떻게 확인할 수 있는지 확인해 보도록 합니다.
먼저 3번 에서 숫자 4를 클릭해 봅시다. 그러자 6번에 새롭게 서버에서 내려받는 정보가 하단으로 주르륵 표시되기 시작합니다. 새로 받은 신호정보를 위에서 부터 차근차근 보니 7번의 sise_index_day.nhn?code=KOSPI&page=4이 눈에 보이네요. 맨 앞에는 sise_index라고 적혀있고 뒤로는 code=KOSPI, page=4라는 단어가 보입니다. 누가 봐도 시세정보를 나타내는게 아닌가 싶을 정도로 명확하게 적혀있네요. 시험삼아 3번 에서 숫자 5부터 7까지 눌러보면서 다시 개발자도구에 올라오는 정보를 확인해봅시다. 차례대로 다음과 인덱스 주소를 확인할 수 있을 것입니다.
- sise_index_day.nhn?code=KOSPI&page=5
- sise_index_day.nhn?code=KOSPI&page=6
- sise_index_day.nhn?code=KOSPI&page=7
뭔가 규칙성을 확인할 수 있지 않습니까? 맞습니다. sise_index_day.nhn?code=KOSPI& 까지는 동일하고 페이지 숫자를 누를 때마다 page=5 숫자만 바뀌는 것을 알 수 있습니다. 여기까지 왔다면 사실 거의 다 끝났습니다.
URL은 어디에???
그런데 앞에서 확인한 sise_index_day.nhn?code=KOSPI&page=4는 인터넷 주소처럼 생기진 않았습니다. 무릇 인터넷 주소라면 https://나 www로 시작해야 하는데 이건 그렇진 않죠. 그렇다면 정확한 URL은 어디서 확인해야 하는냐? 그건 Figure1의 8번 항목의 머리글 탭3에서 확인할 수 있습니다.
Figure1의 8번 항목을 살펴보먄 요청URL4이라고 해서 https://finance.naver.com/sise/sise_index_day.nhn?code=KOSPI&page=4이라는 URL 정보가 나옵니다. 이 주소가 네이버에서 제공하는 KOSPI 일별시세 정보의 4번째 페이지에 해당되는 정보입니다. 바로 그 밑으로 요청 메서드 : GET, 상태 코드 : 200 등등의 정보가 있는데 이러한 내용은 다음 번에 설명하겠습니다.
각설하고, 해당 URL을 인터넷 주소창에 입력해 보면 다음의 그림처럼 표시될 겁니다.
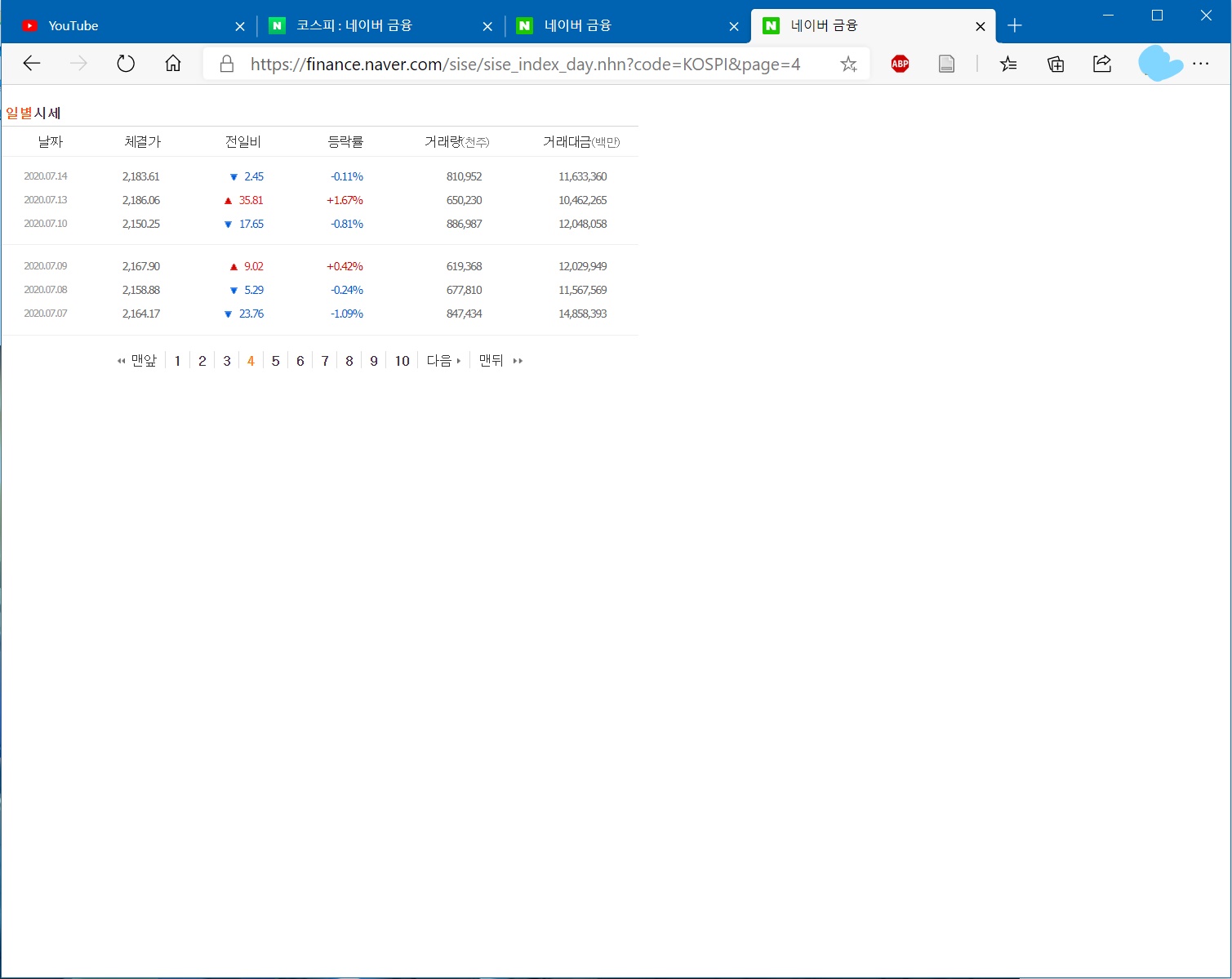
Figure 2: KOSPI 일별시세 정보표시
Figure2는 Figure1에서 표시되는 잡다한 정보를 제거하고 일별시세 정보만 덩그러니 놓여있습니다. Figure2에서 1번 페이지 부터 5번 페이지 까지 클릭하면서 주소표시줄의 URL의 변화를 살펴보면 다음과 같을 것입니다.
- https://finance.naver.com/sise/sise_index_day.nhn?code=KOSPI&page=1
- https://finance.naver.com/sise/sise_index_day.nhn?code=KOSPI&page=2
- https://finance.naver.com/sise/sise_index_day.nhn?code=KOSPI&page=3
- https://finance.naver.com/sise/sise_index_day.nhn?code=KOSPI&page=4
- https://finance.naver.com/sise/sise_index_day.nhn?code=KOSPI&page=5
https://finance.naver.com/sise/sise_index_day.nhn?code=KOSPI& 까지는 동일하고 page=5의 페이지 번호만 변경되는 것을 확인할 수 있을 것입니다. 이제 네이버에서 제공하는 KOSPI 일별시세 정보의 정확한 주소를 확인했습니다.
몇가지 추가
개발자도구 네트워크 탭에 대한 팁…
Figure1의 개발자도구 네트워크 탭에서 5번의 “모두” 항목에 표시되는 정보로 부터 내가 원하는 정확한 신호정보를 찾기란 쉬운게 아닙니다. “모두” 항목은 말 그대로 브라우저에 표시되는 정보의 모든 신호를 표기하기 때문에 웹페이지 하나를 띄울 때마다 엄청난 양의 신호정보가 쌓이기 때문입니다. 좀 더 편하게 확인하려면 5번항목 옆으로 보이는 XHR, CSS,… 등등을 클릭하면서 확인해 보는 것이 좋습니다. 웹페이지 신호를 정보 유형별로 구분해서 보여주기 때문에 내가 찾는 신호를 찾기가 훨씬 수월할 것입니다.
이번 포스트에서 다룬 네이버 KOSPI 일별시세의 경우 5번항목의 “문서5”탭에 나타나 있습니다. 아래의 Figure3이 “문서”항목에서 신호정보를 확인한 것인데 Figure1에서 보다 훨씬 간단하게 일별시세에 대한 신호가 식별됩니다.
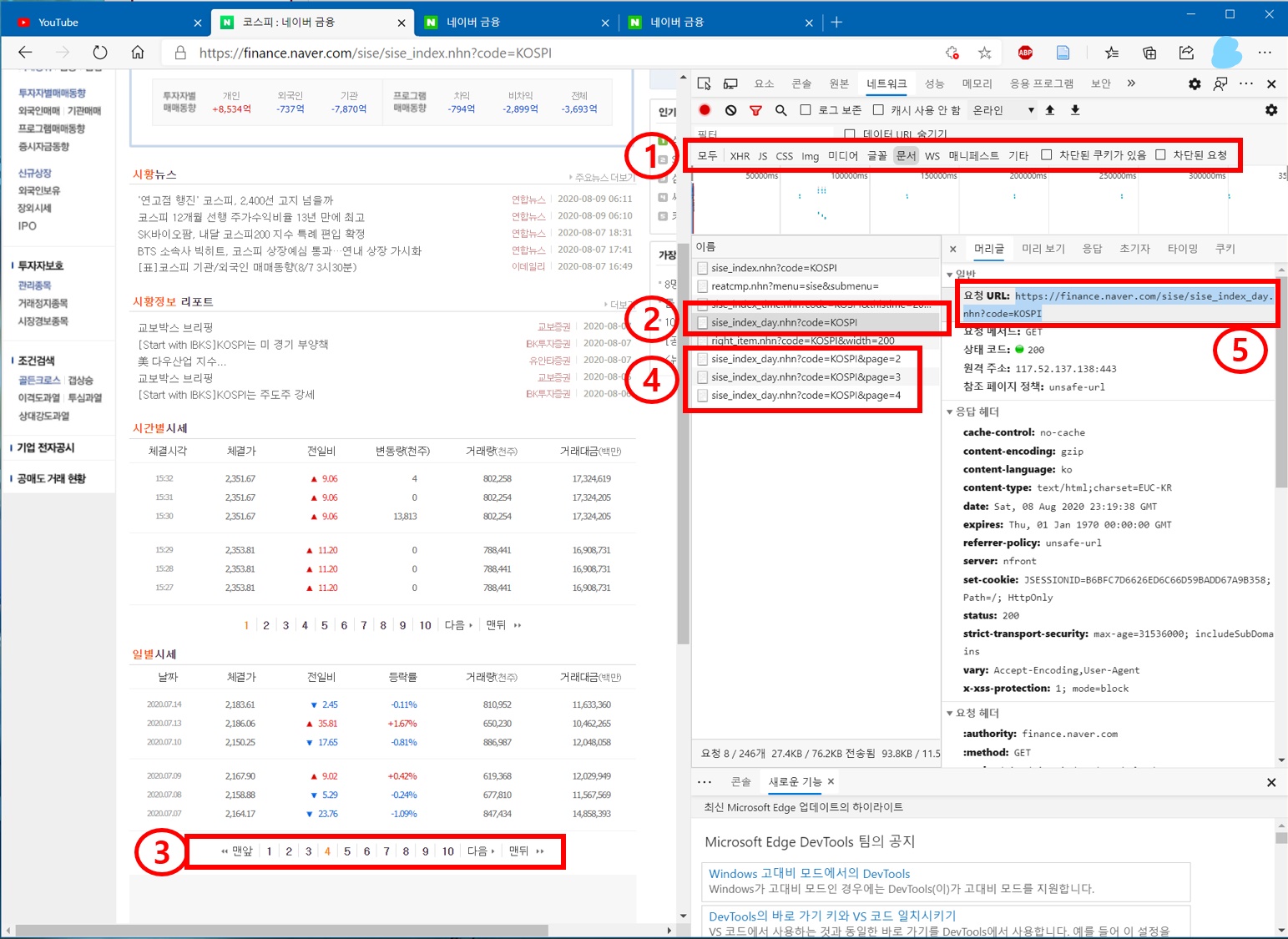
Figure 3: 네트워크의 ’문서’항목
인터넷 주소의 구성

Figure 4: 인터넷 주소의 구성
앞절에서 파악한 URL은 크게 세 부분으로 나뉘어져 있습니다. Figure 4를 보겠습니다.
먼저 “https://” 부터 “.com” 까지 이어지는 도메인 주소가 있습니다. 다른 주소로는 “.kr”, “.org”, “.net”으로 끝나는 인터넷 도메인이 여기에 해당됩니다. 도메인 주소 바로 다음으로는 해당 정보가 위치한 경로, 즉 “/sise/sise_index_day.nhn”이 표시되어 있습니다. 즉, 최상위 호스트인 “https://finance.naver.com” 안에 KOSPI 시세 정보가 위치한 디렉토리6를 표시하고 있는 것입니다. 마지막 부분에는 “?” 이후로 해당 경로에 저장되어 있는 여러 정보 중에서 정확히 어떤 내용을 웹에 표시할 것인지 특정하는 검색쿼리가 붙어있습니다. 여기서는 “code=KOSPI”와 “page=1”이라는 두가지 키워드로 구성되어 있고 각각의 키워드는 “&”로 묶여있습니다.
세 부분의 URL을 종합해서 곱씹어보면 "네이버 증권 서비스(https://finance.naver.com)에서 일별시세(/sise/sise_index_day.nhn)에 관한 자료를 찾는데 KOSPI 지수(code=KOSPI)의 첫번째 페이지(page=1)만 표시하라"는 뜻으로 쉽게 연결이 되네요. 인터넷 주소만 봐도 무슨 내용인지 대충 감이 잡히지 않습니까?
다만, 이러한 URL 구성이 인터넷 요청 메소드 중에서는 GET 요청에 해당되는 것으로, POST 요청에서는 조금 다르게 표현된다는 것을 유의해야 합니다. 예컨대 POST 요청에서는 쿼리 정보가 겉으로 드러나지 않고 “body”의 형태로 숨겨있습니다. 그래서 보안에는 GET 요청 보다 POST 요청이 더 유리하다고 하는데, 자세한 내용은 다음 페이지에서 다루겠습니다.
이후의 웹 페이지에 대한 모든 설명은 구글 크롬 브라우저를 기준으로 합니다. 파이어폭스나 엣지브라우저에서도 동일한 기능을 제공하고 동일한 순서로 크롤링이 진행되지만 보통 인터넷 검색을 통해 얻을 수 있는 대부분의 팁이 크롬을 기준으로 하고 있기 때문에 크롬에 익숙해 지면 향후 혼자서 정보검색할 때에도 편리하다는 장점이 있습니다.↩︎
웹 브라우저의 개발자도구를 표시합니다.↩︎
영문판에서는 “header”로 표기되기도 합니다.↩︎
영문판에서는 “Request URL”로 표시됩니다↩︎
영문으로는 "DOC" 입니다.↩︎
단순하게 “폴더”라고 이해하면 편하겠습니다.↩︎